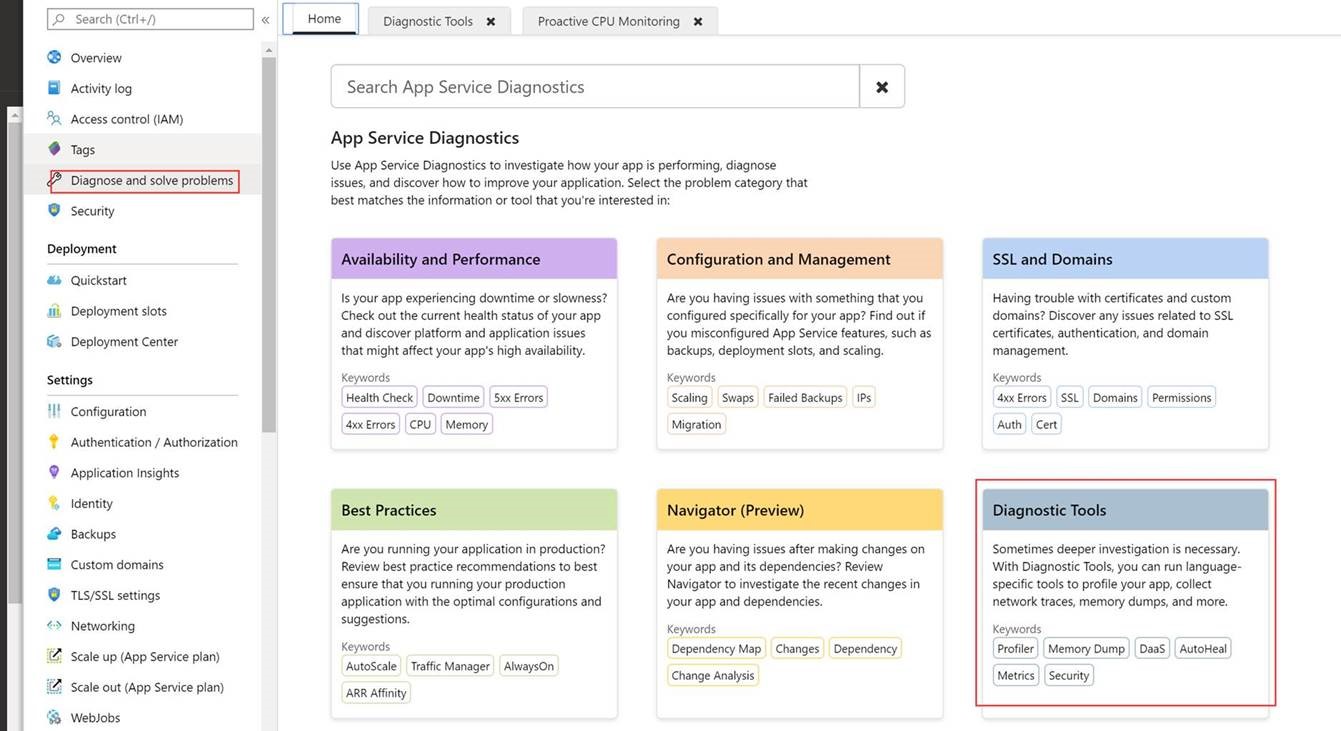
Service discovery solves the problem of figuring out which process is listening on which address/port for which service.
In a good service discovery system:
- users can retrieve info quickly
- informs users of changes to services
- low latency
- richer definition of what the service is (not sure what this means)
- a way to create a named label selector
- created using kubectl expose
- Each service is assigned a virtual IP called cluster IP – the system load balances across this IP all the pods identified by the same selector
Kubernetes itself creates and runs a service called kubernetes which lets the components in your app talk to other components such as the API server.
- k8s inbuilt DNS service maps cluster IPs to DNS names
- installed as a system component when the cluster is created, managed by k8s
- Within a namespace, any pod belonging to a service can be targeted just by using the service name
The Service objects also tracks when your pods are ready to handle requests.
spec:
…
template:
…
spec:
containers:
…
name: alpaca-prod
readinessProbe:
httpGet:
path: /ready
port: 8080
periodSeconds: 2
initialDelaySeconds: 0
failureThreshold: 3
successThreshold: 1
I we add the readinessProbe section to our YAML for the deployment, then the pods created by this deployment will be checked at the /ready endpoint on port 8080. As soon as the pod comes up, we hit that end point every 2 seconds. If one check succeeds, the pod will be considered ready. However, if three checks fail in succession, it’ll not be considered ready. Requests from you application are only sent to pods that are ready.
Looking Beyond the Cluster
To allow traffic from outside the cluster to reach it, we use something known as NodePorts.
- This feature assigns a specific port to the service along with the cluster IP
- Whenever any node in this cluster receives a request on this port, it automatically forwards it to the service
- If you can reach any node in the cluster, you can reach the service too, without knowing where any of its pods are running