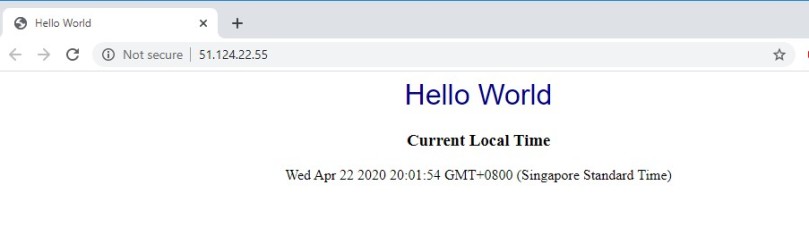
Docker today announced that it has extended its strategic collaboration with Microsoft to simplify code to cloud application development for developers and development teams by more closely integrating with Azure Container Instances (ACI).


Docker and Microsoft’s collaboration extends to other products as well. Docker will add integrations for Visual Studio Code, Microsoft’s widely used free code editor, to let developers who use the tool deploy their code as containers faster. After this collaboration, you can login directly to Azure from Docker CLI, then you can select Docker context. If we have resource group, you can select it or you can create a new resource group. Then, you can run individual or multiple containers using Docker Compose.
docker login Azure
docker context create aci-westus aci --aci-subscription-id xxx --aci-resource-group yyy --aci-location westus
docker context use aci-westus
Tighter integration between Docker and Microsoft developer technologies provides the following productivity benefits:
- Easily log into Azure directly from the Docker CLI
- Trigger an ACI cloud container service environment to be set up automatically with easy to use defaults and no infrastructure overhead
- Switch from a local context to a cloud context to run applications quickly and easily
- Simplifies single container and multi-container application development via the Compose specification allowing a developer to invoke fully Docker compatible commands seamlessly for the first time natively within a cloud container service
- Provides developer teams the ability to share their work through Docker Hub by sharing their persistent collaborative cloud development environments where they can do remote pair programming and real-time collaborative troubleshooting
For more information & developers can sign up for Docker Desktop & VS Code beta here.